An Exploratory Look at Maudet-Danoy Distances and Learned Branching Transfer
Written by Skanda Vyas Srinivasan
Project Repo: https://github.com/skanda-vyas-srinivasan/Branch-Learning-Transfer
Introduction
Learned branching policies replace traditional heuristics in branch-and-bound by leveraging machine learning to mimic strong branching patterns at a fraction of the overhead. However, they are heavily constrained.
These models are generally trained on a specific MILP problem distribution, making them very reliable at solving instances within their training class. However, their performance often degrades significantly on out-of-distribution instances.
This raises important questions: what if two problem instances are different but structurally similar? Could a model trained on one be helpful to solve the other? Conversely, if an instance is structurally far from the training instance, would the learned policy become even less reliable?
This post details an independent, exploratory project that uses Maudet-Danoy Distances to examine whether structural similarity between MILP instances can predict the transferability of a learned branching policy across problem classes. I train a Learn2Branch-style graph neural network branching policy on set-cover instances, then evaluate how its performance changes across other MILP problem classes as their Maudet-Danoy distances increase.
Just as a disclaimer, this is an exploratory technical blog post, not a definitive research paper. I used the instance generators provided by the L2B framework, which produce instances that cluster into only four distinct distance groups. This means the results show a pattern but are not statistically conclusive. I’m sharing what I built and learned, not claiming a definitive result.
Definitions
Before we get started on the actual problem, I’ll go over some of the ideas that we will use in this post. I’ll be very brief and have linked material that are good resources for readers who would like a more detailed treatment of any of these topics.
Mixed-Integer Linear Program
Following the formulation given in the Conforti, Cornejouls, and Zambelli textbook, A Mixed-Integer Linear Program (MILP) is a problem of the form:

Here, x represents the integer decision variables and y represents the continuous decision variables. c and h are vectors that define the linear objective, and the matrices A, G, and b define the linear constraints. Keep in mind, the difference between a MILP and a Linear Program is the integrality constraints for x.
Branch and Bound is an algorithm that is used to optimally solve Mixed-Integer Linear Programs. It first solves the linear relaxation of the problem. If the solution is fractional, the solver branches on one of the fractional variables, creating smaller subproblems and forming a search tree. Good branching decisions can make this tree much smaller, which is why learned branching is very useful.
Some great resources on Linear and Integer Programming are listed below:
-
Alberto Del Pia, Linear Optimization Playlist
-
Alberto Del Pia, Integer Optimization Playlist (Incomplete)
-
Dimitris Bertsimas and John N. Tsitsiklis, Introduction to Linear Optimization
-
Michele Conforti, Gérard Cornuéjols, and Giacomo Zambelli, Integer Programming
Machine-Learning Augmented Branching
Generally, in a branch and bound MILP solver, branching helps decide which variable to split on when the relaxation is fractional. ML Augmented branching replaces a traditional heuristic choice of variables with a learned model that guides the choice by scoring candidate variables. In this project, the learned model does not solve the MILP directly. It only influences the branching decisions made inside SCIP.
Some great resources if you want to learn more about this topic:
-
Scavuzzo et al., Machine learning augmented branch and bound for mixed integer linear programming Mathematical Programming, 2024.
Maudet-Danoy Distances
Maudet and Danoy detail a metric for comparing MILP instances based on their structural similarity. The metric compares the constraints, variables, and coefficients across two MILPs and measures how different their structures are. In this project, I use this distance to measure how close a test instance is to the training set. Although there is no formal name for this metric, we will refer to it as the Maudet-Danoy distance throughout the post.
For more details on the Maudet-Danoy Distance metric:
Maudet and Danoy, A Distance Metric for Mixed Integer Programming Instances
Experiment Setup
Training the Model
The experiment uses a Learn2Branch (L2B) branching policy trained on a particular set cover distribution: instances with 500 rows, 1000 columns, and a density of 0.05. The policy uses a graph convolutional neural network architecture, where each MILP state is represented as a bipartite graph. Constraints represent the constraint nodes, and decision variables represent the variable nodes; non-zero coefficients define the edges connecting them.
For example, consider this small integer program with three variables and two constraints.

The bipartite representation has one node for each constraint, namely and , and one node for each variable , , and . An edge is added whenever a variable has a non-zero coefficient in the constraint. Hence, is connected to and with edges of coefficients 1 and 2, respectively. is connected similarly.
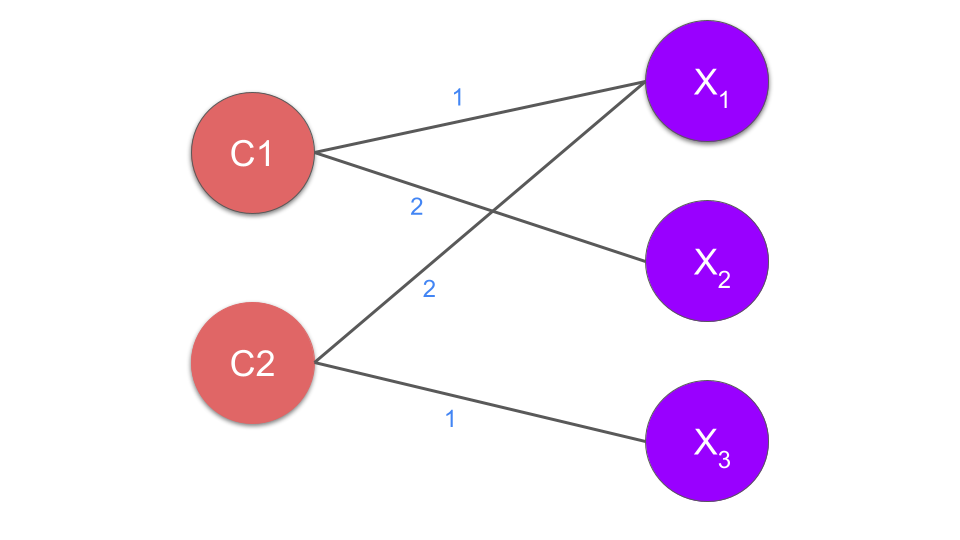
The significance of the bipartite graph is that it preserves the natural variable-constraint structure of an MILP. This gives the Graph Convolutional Neural Network (GCNN) a structured view of the MILP. The variables are not scored in isolation, but in relation to the constraints they appear in and the other variables related to those constraints.
Experiment Design
After training, I keep the learned policy fixed and evaluate it on unseen set-cover instances and out-of-distribution (OOD) MILP classes. These OOD classes are, namely, combinatorial auctions, capacitated facility location, and independent set. For each test instance, I estimated its distance from the training distribution by averaging its Maudet-Danoy distance to a reference set of set-cover instances. We have 100 instances from each of the four test classes, for a total of 400.
Each instance is then solved twice. Once with vanilla SCIP branching, and once again with the learned policy. To compare performance of the model on the testing instances, I defined a metric relative node count which is the number of branch and bound nodes explored by the learned policy divided by the number of nodes explored by the vanilla SCIP solver. Hence, the lower the relative node count, the better the model performs on that instance.
The main hypothesis is that Maudet-Danoy distances should be positively correlated with relative node count. For the experiment to be meaningful, a test instance with a low Maudet-Danoy distance to the training distribution should be better suited for the learned policy than one with a high distance. In other words, as the Maudet-Danoy distance increases, the relative node count should also increase.
Test Set Profile
Before we move on to the solver performance and results, I think it’s useful to diverge and discuss the distance profile of the test set. The test set is constructed using the generators provided in the L2B repository. Since test classes were all generated from fixed-instance distributions, most OOD classes have very little in-class distance variation. Therefore, this experiment mainly tests whether problem classes that are structurally farther from the set-cover exhibit worse transfer of the learned branching policy. We will discuss this further in the Next Steps section of this post.
The final experiment uses 100 instances per class, for a total of 400. The class-level Maudet-Danoy distances from the reference set were approximately:
-
setcover_valid: 0.0034 (Set Cover)
-
cauctions: 2.0102 (Combinatorial Auctions)
-
indset: 2.9899 (Independent Set)
-
facilities: 3.001 (Capacitated Facility Location)
Results
I compare the relative node counts (RNC) across the four test classes and examine how they change with Maudet-Danoy distance from the reference set. The final analysis uses 100 instances from each class: setcover_valid, cauctions, indset, and facilities
Figure 1 shows the relationship between the Maudet-Danoy distance from the reference set and RNC. The first thing to notice is that the points are not evenly spaced along the x-axis. Instead, they form vertical clusters because each test class was generated from a fixed distribution. Since RNC varies widely, the y-axis is shown on a log scale.
Figure 1
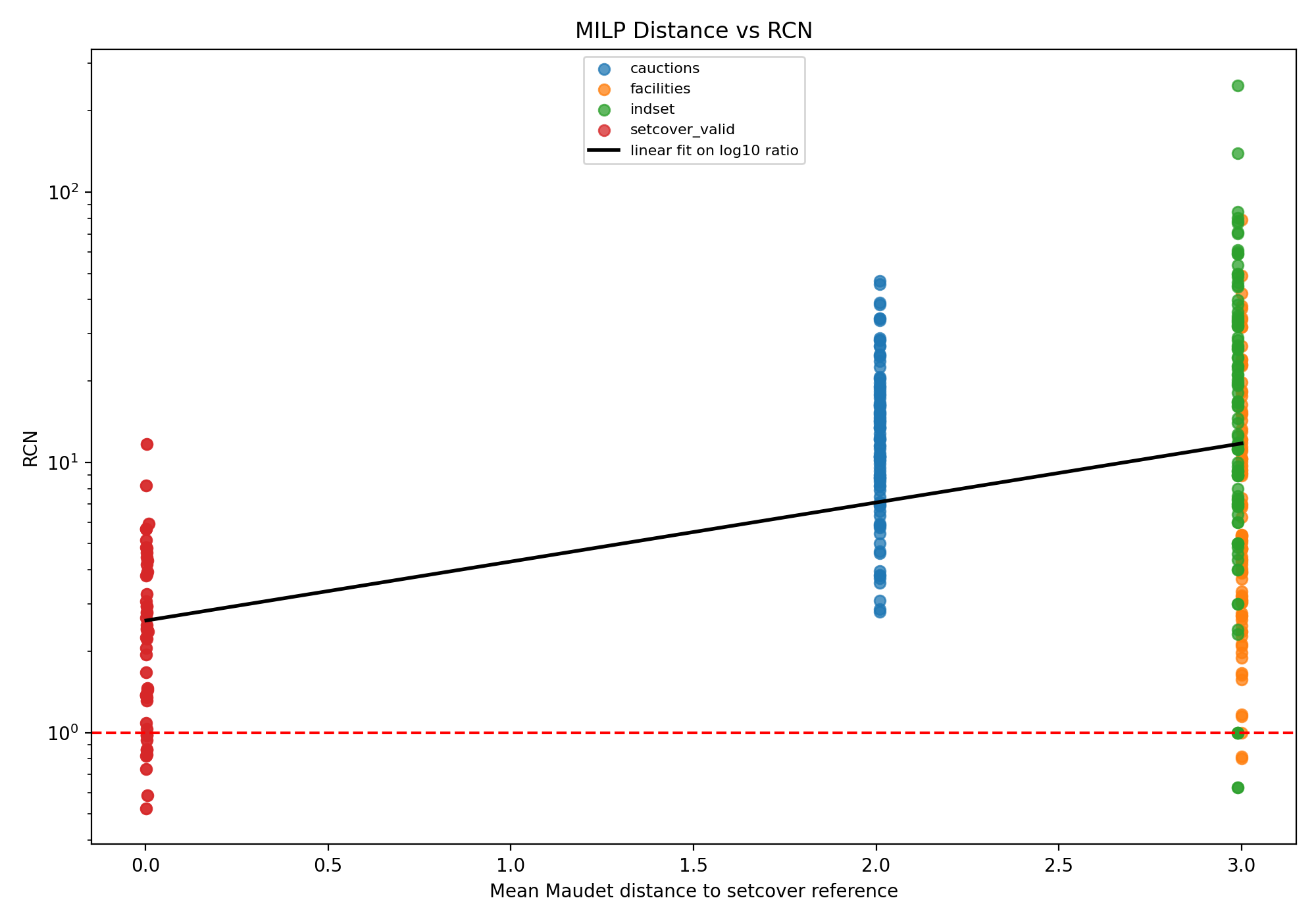
The setcover_valid instances were clustered near zero, and show a relatively low spread of RNC values. The mean RNC was 2.83 and the median RNC was 2.39 for all 100 instances.
The cauction instances were clustered near distance 2, and show a relatively elevated spread of RNCs with mean 14.52, and median 12.30. As these instances were OOD, it is reasonable to observe an elevated RNC value compared to setcover_valid instances.
The facility and indset instances are both clustered around distance 3. However, the important point is that, despite being at a similar distance, their RNCs are not identical. For facility, the mean RNC is 10.82 and the median RNC is 5.38. For indset, the mean RNC is 26.30 and the median RNC is 16.68.
Figure 2
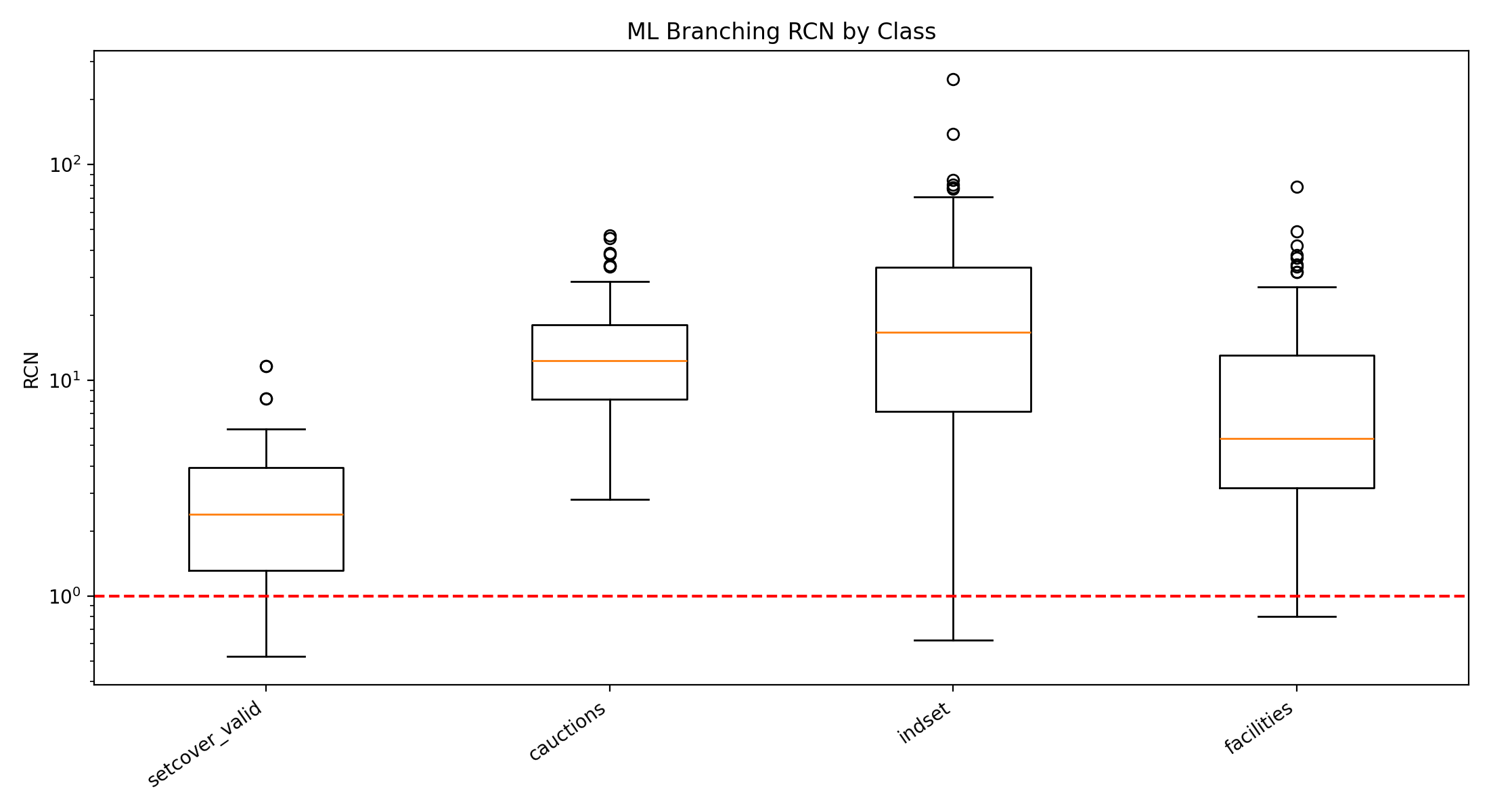
What’s even more interesting is that the spread of RNC values for cauctions is actually greater than that of the facility. Looking at Figure 2, we can see that the facility has a lower median RNC but also a wider distribution, with several high-RNC outliers. This implies that facility instances aren’t simply easier for the learned policies. Rather, its behavior is mixed across instances. In most facility instances, the learned policy stays relatively close to the SCIP baseline, thereby lowering the median RNC. However, there are also a good number of facilities that produce much larger search trees, which creates the long upper tail in the boxplot. Combinatorial auctions, by contrast, are more evenly distributed around a consistently high RNC range.
Figure 3
| Class | N | Mean Maudet-Danoy Distance | Median SCIP Nodes | Median ML Nodes | Mean RNC | Median RNC |
|---|---|---|---|---|---|---|
| Set-cover validation | 100 | 0.0034 | 91 | 199 | 2.83 | 2.39 |
| Combinatorial auctions | 100 | 2.0102 | 11 | 125 | 14.52 | 12.30 |
| Independent set | 100 | 2.9899 | 12 | 246.5 | 26.30 | 16.68 |
| Capacitated facility location | 100 | 3.0001 | 84 | 480 | 10.82 | 5.38 |
This points to an important interpretation of the results. Maudet-Danoy distance is useful for separating the training distribution from structurally different problem families, but it should not be treated as a complete ordering of transfer difficulty. In this experiment, the set-cover validation instances sit near distance zero and have the lowest RNC values overall, while the OOD classes are farther from the training distribution and generally have higher RNC values. There is also evidence of higher-risk behavior at greater distances, such as upper-tail failures in facility location. However, the differences across cauctions, facility, and indset show that distance alone is not sufficient to fully explain transfer behavior. I discuss this in more detail in the next section.
The fitted line in Figure 1 summarizes the aggregate trend. The fit is computed after taking the log of the RNC values. The upward slope suggests a positive relationship at the class level, but the limited distance clusters mean this should be interpreted cautiously.
Discussion
Interpreting the results
The results suggest that Maudet-Danoy distance may capture a useful signal related to the performance of a learned policy. The learned branching policy performs best near the set-cover training distribution and becomes less reliable for problem classes farther away. This is consistent with the project’s central idea that structural similarity may be relevant when evaluating whether a learned branching policy will transfer to a new class of MILPs.
However, it is also clear that Maudet-Danoy distance should be interpreted as an initial baseline test rather than a complete reliability predictor. Although the metric captures structural differences between MILPs, the branching behavior also depends on how the search process is affected by those structures. Two problem classes can be similarly distant from set covers while still exhibiting completely different search behavior.
This means the main value of the Maudet-Danoy distance is not that it perfectly orders problems by transfer difficulty, but rather that it serves as a cautionary signal for distribution shift. In this experiment, low distances were associated with lower relative node counts, whereas larger distances were associated with larger relative node counts. These results should therefore be interpreted as a measure of degradation under a shift in distribution rather than a successful transfer of a learned branching policy.
Limitations and Next Steps
A major limitation of this experiment is the reliability of the learned branching policy itself. The L2B policy did not consistently outperform SCIP even within its own training distribution. This limits the strength of any results or takeaways, as poor OOD performance can also be attributed to weaknesses in the base policy. A stronger follow-up to this project would include a learned-branching policy that clearly improves over SCIP in-distribution, then test whether Maudet-Danoy distance predicts where that advantage begins to disappear.
Another limitation is that the test instances don’t provide a continuous range of Maudet-Danoy distances. Because the experiment uses exclusively the problem generators provided by L2B, the instances cluster into discrete distance pockets. The current experiment, therefore, appears more like a class-level transfer study, where the Maudet-Danoy distance helps compare broad problem families, rather than an instance-level study.
Future work should expand the scope of testing instances in two directions. First, it should include more MILP problem families so that the test set covers a wider range of discrete Maudet-Danoy pockets rather than only a few clusters. Second, it should evaluate multiple distributions within each problem family by manipulating parameters. This will increase the within-class distance variation. Overall, this would create a richer collection of instances that better approximates a continuous range of Maudet-Danoy distances.
Conclusion
This project studied whether Maudet-Danoy distance can explain how learned branching policies transfer across MILP problem classes. The results suggest that there may be a positive relationship between Maudet-Danoy distances and relative node counts. This is consistent with the idea that formulation similarity may be relevant when evaluating whether a learned branching policy will generalize outside of its training distribution.
At the same time, the results should be viewed as an initial step rather than a complete transferability test. The learned policy was not consistently stronger than SCIP on instances within the distribution, and the test instances occupied only a few discrete distance pockets. Future work should evaluate stronger learned-branching policies across more MILP families and multiple distributions within each family. This would make it possible to better understand whether Maudet-Danoy distance predicts successful transfer.
References
- Maudet and Danoy, A Distance Metric for Mixed Integer Programming Instances
- Gasse et al., Exact Combinatorial Optimization with Graph Convolutional Neural Networks